تشخیص اعلام،نمایه زنی و به کارگیری آن به عنوان زیر ساخت سایر فرآیندهای ماشینی از اهم مواردی است که به تشخیص موجودیت نامدار نیازمندیم. اسامی اشخاص، افراد، اماکن و نهادها و مواردی از این دست، نیاز پایه محققان در بسیاری از رشتهها است. به دلایل مذکور و با توجه به هزینهی بالای تشخیص موجودیت نامدار به صورت دستی و توسط عامل انسانی، توسعه موتور تشخیص موجودیت نامدار در مرکز تحقیقات کامپیوتری علوم اسلامی (نور) در دستور کار قرار گرفته است.
امروزه برای عبارت “موجودیت نامدار” تعاریف متعددی به چشم می خورد. تا جایی که در برخی منابع، تا 19 تعریف متفاوت از موجودیت نامدار ارائه شده است. به طور کلی، موجودیتهای نامدار، اسامی موجودیتهای دلخواه ما در یک متن دلخواه (مثل نام اشخاص، مکانها، داروها و بیماریها و …) هستند.
تشخیص موجودیتهای نامدار دارای کاربردهای وسیعی شامل: پرسش و پاسخ، بازیابی اطلاعات، استخراج اطلاعات، تحلیل روند، طبقه بندی اسناد، خلاصه سازی، برچسب زنی خودکار متن، ترجمه ماشینی، استخراج نمایه و اعلام و بسیاری کاربردهای بالقوهی دیگر است.
تا به امروز، سه رویکرد سنتی برای تشخیص موجودیت های نامدار ارائه شده است و سیستم های مدرن تشخیص موجودیتهای نامدار عمدتا از ترکیب این سه روش استفاده میکنند:
روشهای مبتنی بر واژه نامه
روشهای مبتنی بر قواعد
روش های مبتنی بر یادگیری ماشین.
سامانه تشخیص موجودیت نامدار مرکز تحقیقات کامپیوتری علوم اسلامی با استفاده از جدید ترین فناوری یادگیری ماشین یعنی یادگیری عمیق و در دوزبان فارسی و عربی توسعه داده شده است. یادگیری عمیق نوع رویکرد نوینی در هوش مصنوعی و یادگیری ماشین است که در دههی گذشته به عنوان رویکرد غالب در زمینههای مختلف به کار رفته است. استفاده از فناوری هوش مصنوعی باعث شده است که
عملکرد مورد نظر سیستم بدون استفاده از واژگان انجام پذیرد. این مهم باعث خواهد شد تا کلمهای واحد که در دو متن متفاوت در دو جایگاه متفاوت است به درستی تفسیر شود.(شکل 1)
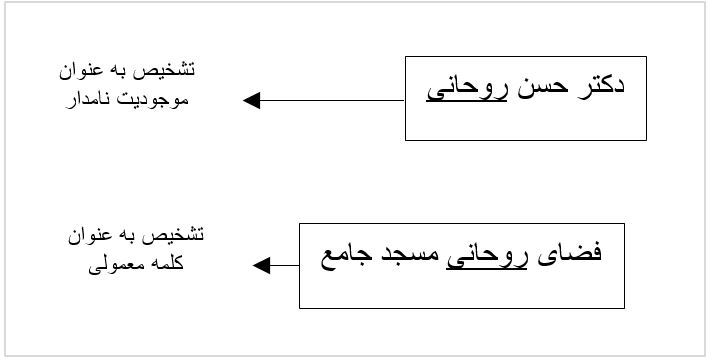
موتور تشخیص موجودیت نامدار مرکز نور، در دوزبان عربی و فارسی توسعه داده شده است. طراحی این سامانه به گونهای است که تنها با تولید دادهی آموزش، میتواند برای سایر زبانها عملیات تشخیص موجودیت نامدار را انجام دهد.[1]
استفاده از پردازش رایانشی در تشخیص موجودیت نامدار و همچنین استفاده از هوش مصنوعی در این مسیر، موتور موجودیتهای نامدار را حائز برتری هایی ساخته که به شرح ذیل میباشد:
پردازش حجم انبوهی از دادهها در زمانی بسیار کم
تشخیص موجودیتهای نامدار دیده نشده به دلیل در نظر گرفتن اطراف کلمه به عنوان شواهد.
امکان توسعهی این موتور برای سایر زبانها با صرف هزینهی بسیار کم
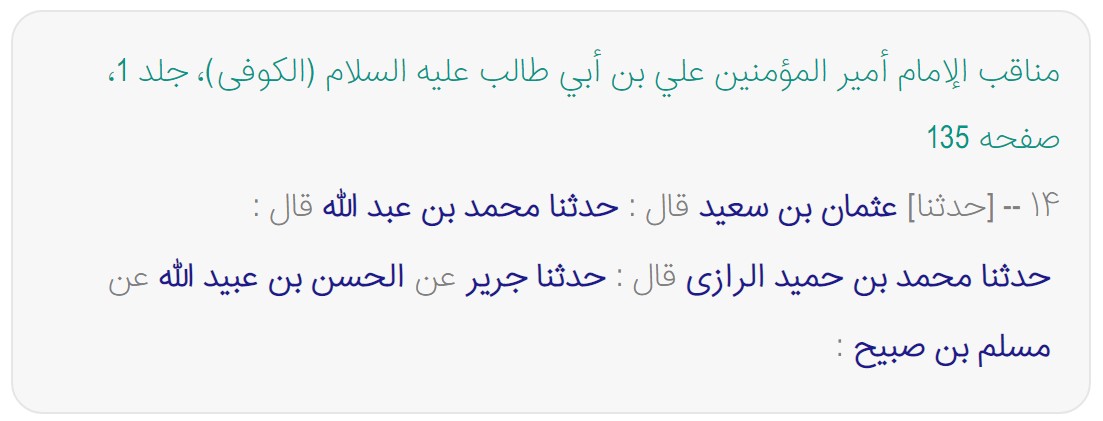
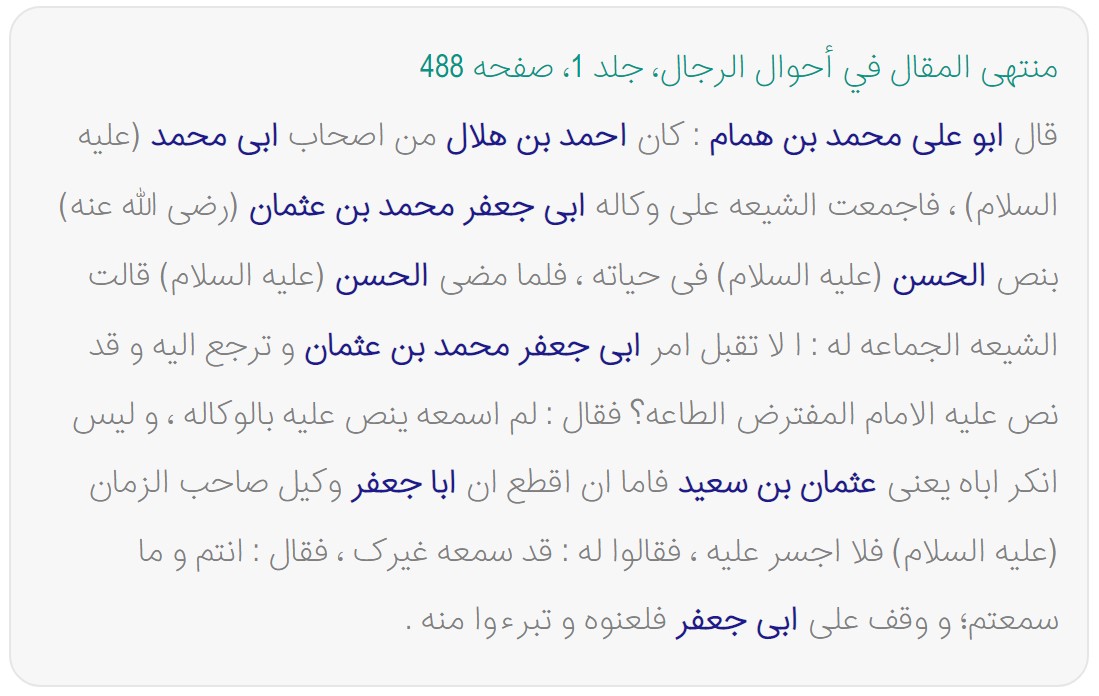
عدم استفاده صرف واژگان برای تشخیص موجودیت نامدار.
تشخیص موجودیت نامدار دارای استفادههای متعددی است. با توجه به محصولات محوری مرکز و چشم انداز آنها گام های زیر برای به کار گیری موتور تشخیص موجودیت نامدار متصور است.
مجتمع کردن موتور تشخیص موجودیت نامدار و موتور جست و جوی نورمگز جهت ارائهی نتیجهی بهتر در مواجهه با اعلام
ایجاد برگهی اعلام در وب سایت نورلیب به ازای هر کتاب
کمک به توسعهی هستان شناسیهای مورد نیاز در پروژههای هوشمند نور
همچنین در جهت بهبود استفاده از خروجی موتور تشخیص موجودیت نامدار لازم است دو گام اساسی انجام شود:
رفع ابعام از موجودیت نامدار به معنای آن است که چنانچه در یک متن انواع مختلفی از نامهای یک موجودیت خاص
وجود دارد، این نامهای متنوع با یکدیگر متصل شوند تا زمینه برای گام بعدی یعنی ارجاع اعلام فراهم شود
ممکن است دو فرد متفاوت یا دو مکان متفاوت اسامی مشابهی داشته باشند. در چنین شرایطی خروجی ایدهآل این است که اعلام رفع ابهام شده به یک شاخص یکتا متصل شوند تا در فرآیند پردازش و بازیابی اطلاعات، دچار خطای تشابه اسمی نشویم.
استفاده از این موتور در تولید نمایهها، فرهنگنامه ها و همچنین در تحلیل محتوایی اطلاعات، پژوهش کیفی، بازیابی اطلاعات میتواند باعث کاستن از هزینهی عملیات انسانی و طبعا تسریع در روند پژوهشها شود.
اضافه شدن خروجی این محصول به سایر محصولات مرکز نور مثل وب سایت نورمگز و یا حتی نرم افزارهای رومیزی مرکز نور میتواند باعث تکمیل اکوسیستم پژوهشی نرمافزارهای نور بشود.