در سالهای اخیر مساله زبانشناسی محاسباتی یکی از دغدغههای محققین حوزه کامپیوتر و زبانشناسی شده است. استفاده از کامپیوتر و ابزارهای هوشمند باعث شدهاند که بتوان بسیاری از کارهای مرتبط با متن را با سرعت و دقتی قابل توجه انجام داد. علاوهبراین، قدرت وارد شدن به عرصههایی را که تصور آنها نیز مشکل بوده فراهم کرده است. برای نمونه ترجمه هوشمند، جستجوگرهای معنایی و بسیاری از کارهای دیگر در این زمینه را میتوان نام برد. همچنین هر یک از زبانهای موجود در دنیا به تنهایی میتوانند مخاطب تمامی پردازشهای زبانی قرار گیرد.
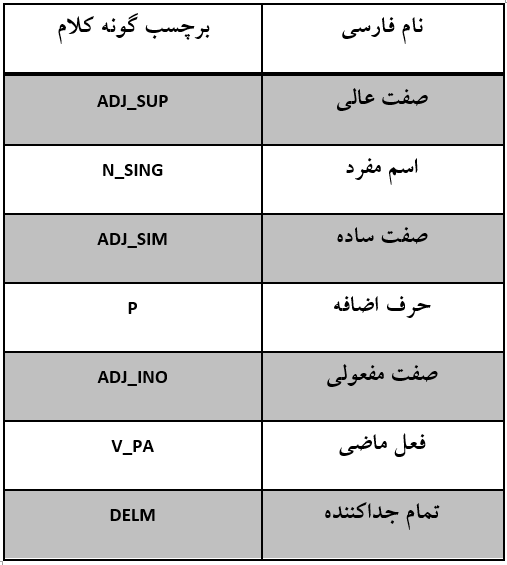
برچسب گذاری ادات سخن به معنای بدست آوردن گونه صرفی کلمات یک متن است. برای نمونه و با فرض داشتن مجموعه برچسبهای زیر:

استفاده از مدل مخفی مارکوف جهت برچسبگذاری گونههای کلام میتواند به عنوان یک برداشت از تئوریهای احتمالی دانست. این فرآیند به شرحی که در ادامه میآید اجراء میگردد:
سؤال این است که، برای یک رشته از کلماتگرفته شده، چه ترتیب برچسبی بهترین ترتیب برچسب برای آن رشته کلمات است؟ اگر ما متن ورودی را (ترتیبی از واحدهای صرفی در کار ما) بصورت W = (wi)1<i<n نمایش دهیم و یک ترتیب از برچسبهای مجموعه برچسب را با T = (ti)1<i<n مشخص کنیم، هدف ما این است که مقدار زیر را محاسبه کنیم:
![]()
رابطه بیانگر احتمال تعلق گرفتن رشته برچسبهای T به رشته کلمات Wاست. بوسیله استفاده از قاعده بیز و حذف کردن بخش P (W)، رابطه به صورت زیر میتواند تغییر داده شود:
![]()
P (TlW) احتمال رخداد این ترتیب برچسب (احتمالات مربوط به انتقال برچسبها) را نشان میدهد و میتواند توسط مدل N-gram زیر محاسبه گردد:
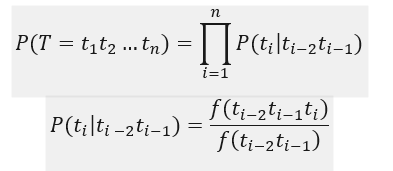
نحوه نرمال سازی :
![]()
به طوری که.
![]()
نحوه محاسبه نیز به صورت زیر میباشد:
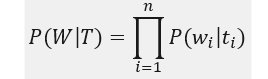
در این پروژه برای انجام آزمایشها از پیکره بیجنخان که یک پیکره متنی استاندارد است استفاده کردهایم. این پیکره تقریبا شامل 2.6 ملیون (2,597,937) کلمهی برچسب خورده از پیکره همشهری است.مجموعه برچسب به کار رفته در این پیکره متنی از 40 برچسب تشکیل یافته که هر یک از آنها بیانکننده یک نوع گونهی صرفیاست. برای آزمایش، از این پیکره، دو میلیون کلمه را به عنوان داده آموزشی و مابقی را به عنوان داده مورد آزمایش انتخاب کردهایم. در میان دو میلیون کلمهی ابتدایی، از 40 برچسب موجود، 39 برچسب آن دیده شد،که مجموعه برچسب مطابق با آن تغییر یافت.
دقت | بازخوانی | معیار F |
94.3% | 94.3% | 94.3% |